
I am a Ph.D. candidate at the Computer Vision and Active Perception Lab at the Royal Institute of Technology (KTH) in Stockholm, Sweden. My advisors are Danica Kragic and Carl Henrik Ek.
My research spans the areas of robotics, computer vision and machine learning. I am interested in developing a representation of household objects that serves a wide range of robotics applications, such as object detection and classification, inferring object affordances, object grasping and manipulation.
I focus on representing visual, depth and tactile data obtained during object grasping.
More details about my projects can be found here.
Recently, I have been visiting the Robotics and State Estimation Lab at the University of Washington in Seattle, USA working with Dieter Fox and Liefeng Bo on representing time series of tactile data using deep unsupervised feature learning methods (our ICRA'14 paper).
I was also involved in the EU GRASP project directed towards the development of a cognitive system capable of performing grasping and manipulation tasks in open-ended environments. This involved collaboration and short research visits to the High Performance Humanoid Technologies Lab at the Karlsruhe Institute of Technology (KIT), Germany and the Vision4Robotics Lab at the Vienna University of Technology (TUW), Austria.
What I do?
- Computer Vision
- Robotics
- Machine Learning
- Object Recognition
- Object Grasping
- Object Affordances
- Deep Learning
- Probabilistic Models
- RGB-D Descriptors
- 3D Point Clouds
- Tactile Data
- Haptic Feedback
Highlights



News
Source code of our Spatio-Temporal Hierarchical Matching Pursuit (ST-HMP) features presented in the ICRA'14 paper is now available here.
I have started a research visit at the Dieter Fox's Robotics and State Estimation Lab at the University of Washington to work on a representation of tactile data.
I received the Google Scholarship for women and minority students in Computer Science.
Our paper is a finalist for the Best Cognitive Paper award in IROS'12! It is here: "Improving Generalization for 3D Object Categorization with Global Structure Histograms (GSH)"
Publications
Peer Reviewed Conference Papers

Abstract
Tactile sensing plays an important role in robot grasping and object recognition. In this work, we propose a new descriptor named Spatio-Temporal Hierarchical Matching Pursuit (ST-HMP) that captures properties of a time series of tactile sensor measurements. It is based on the concept of unsupervised hierarchical feature learning realized using sparse coding. The ST-HMP extracts rich spatio-temporal structures from raw tactile data without the need to pre-define discriminative data characteristics.
We apply the ST-HMP to two different applications: (1) grasp stability assessment and (2) object instance recognition, presenting its universal properties. An extensive evaluation on several synthetic and real datasets collected using the Schunk Dexterous, Schunk Parallel and iCub hands shows that our approach outperforms previously published results by a large margin.
Abstract
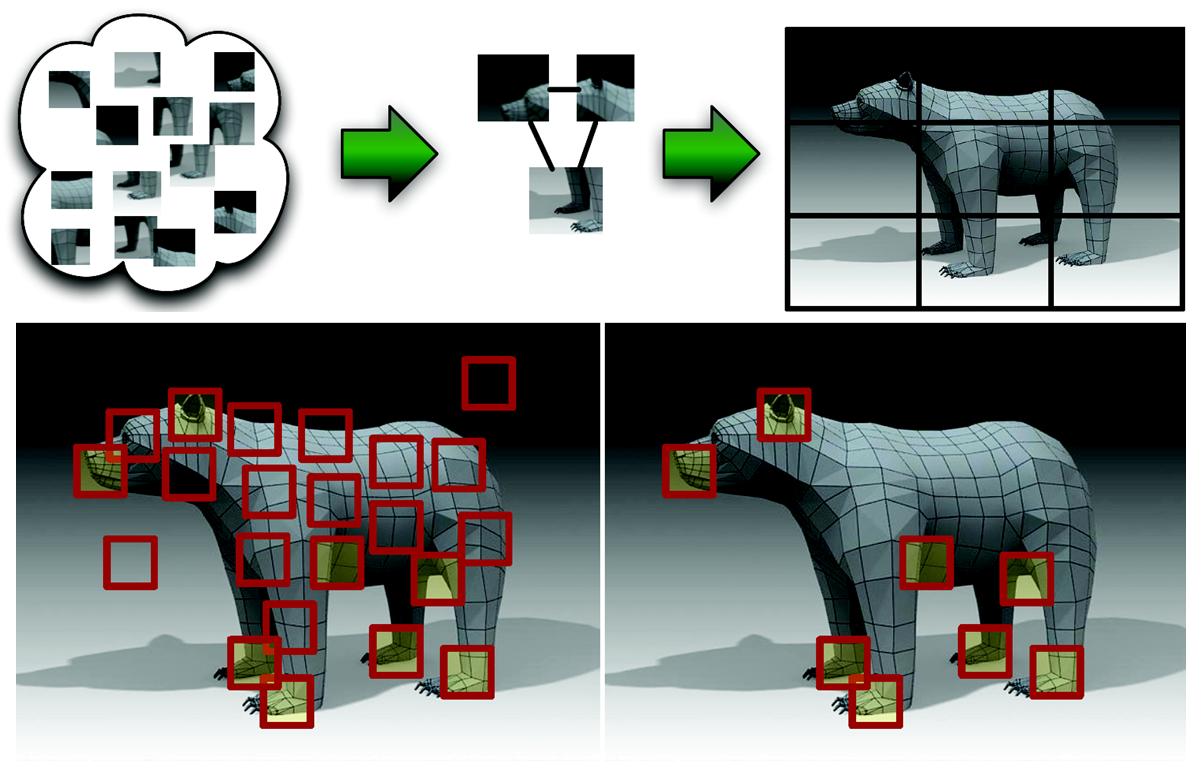
Most object classes share a considerable amount of local appearance and often only a small number of features are discriminative. The traditional approach to represent an object is based on a summarization of the local characteristics by counting the number of feature occurrences. In this paper we propose the use of a recently developed technique for summarizations that, rather than looking into the quantity of features, encodes feature quality to learn a description of an object.
Our approach is based on extracting and aggregating only the essential characteristics of an object class for a task. We show how the proposed method significantly improves on previous work in 3D object categorization. We discuss the benefits of the method in other scenarios such as robot grasping. We provide extensive quantitative and qualitative experiments comparing our approach to the state of the art to justify the described approach.
Abstract
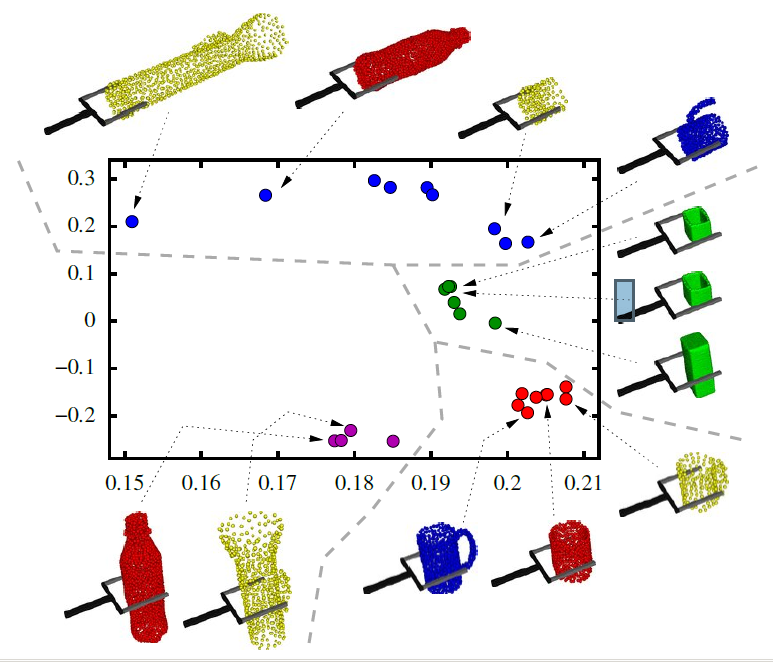
We present a real-world robotic agent that is capable of transferring grasping strategies across objects that share similar parts. The agent transfers grasps across objects by identifying, from examples provided by a teacher, parts by which objects are often grasped in a similar fashion. It then uses these parts to identify grasping points onto novel objects. We focus our report on the definition of a similarity measure that reflects whether the shapes of two parts resemble each other, and whether their associated grasps are applied near one another. We present an experiment in which our agent extracts five prototypical parts from thirty-two real-world grasp examples, and we demonstrate the applicability of the prototypical parts for grasping novel objects.
Abstract
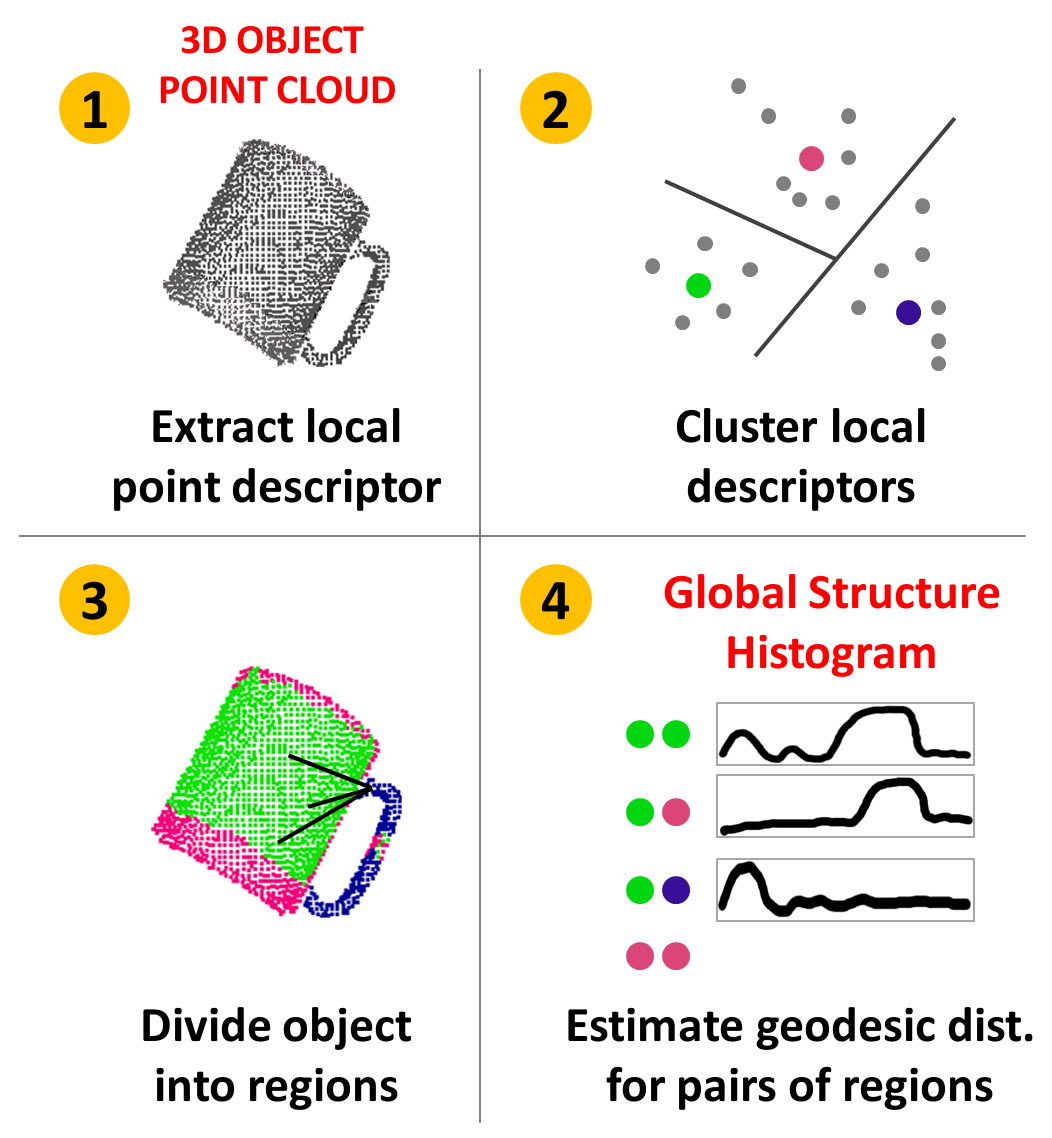
We propose a new object descriptor for three dimensional data named the Global Structure Histogram (GSH) that encodes the structure of a local feature response on a coarse global scale, providing a beneficial trade-off between generalization and discrimination. Encoding the structural characteristics of an object allows us to retain low local variations while keeping the benefit of global representativeness. In an extensive experimental evaluation, we applied the framework to category-based object classification in realistic scenarios. We show results obtained by combining the GSH with several different local shape representations, and we demonstrate significant improvements to other state-of-the-art global descriptors.
Abstract
In this paper we address the problem of grasp generation and grasp transfer between objects using categorical knowledge. The system is built upon an (1) active scene segmentation module, able of generating object hypotheses and segmenting them from the background in real time, (2) object categorization system using integration of 2D and 3D cues, and (3) probabilistic grasp reasoning system. Individual object hypotheses are first generated, categorized and then used as the input to a grasp generation and transfer system that encodes task, object and action properties. The experimental evaluation compares individual 2D and 3D categorization approaches with the integrated system, and it demonstrates the usefulness of the categorization in task-based grasping and grasp transfer.
Abstract
We review the challenges associated to grasp planning, and the solutions that have been suggested to address these challenges in robot grasping. Our review emphasizes the importance of agents that generalize grasping strategies across objects, and that are able to transfer these strategies to novel objects. In the rest of the paper, we then devise a novel approach to the grasp transfer problem, where generalization is achieved by learning, from a set of grasp examples, a dictionary of object parts by which objects are often grasped. We detail the application of dimensionality reduction and unsupervised clustering algorithms to the end of identifying the size and shape of parts that often predict the application of a grasp. The learned dictionary allows the agent to grasp novel objects which share a part with previously seen objects, by matching the learned parts to the current view of the new object, and selecting the grasp associated to the best-fitting part. We present and discuss a proof-of-concept experiment in which a dictionary is learned from a set of synthetic grasp examples. While prior work in this area focused primarily on shape-analysis (parts identified, e.g., through clustering, or salient structure analysis), the key aspect of this work is the emergence of parts from both object shape and grasp examples. As a result, parts intrinsically encode the intention of executing a grasp.

Abstract
In this paper, we present an approach towards autonomous grasping of objects according to their category and a given task. Recent advances in the field of object segmentation and categorization as well as task-based grasp inference have been leveraged by integrating them into one pipeline. This allows us to transfer task-specific grasp experience between objects of the same category. The effectiveness of the approach is demonstrated on the humanoid robot ARMAR-IIIa.
Workshop Papers
Abstract
In this paper we address the problem of grasp generation and grasp transfer between objects using categorical knowledge. The system is built upon an i)~active scene segmentation module, able of generating object hypotheses and segmenting them from the background in real time, ii)~object categorization system using integration of 2D and 3D cues, and iii)~probabilistic grasp reasoning system. Individual object hypotheses are first generated, categorized and then used as the input to a grasp generation and transfer system that encodes task, object and action properties. The experimental evaluation compares individual 2D and 3D categorization approaches with the integrated system, and it demonstrates the usefulness of the categorization in task-based grasping and grasp transfer.
Monographs

Abstract
The ability to perform automatic recognition of human gender is important for a number of systems that process or exploit human-source information. The outcome of an Automatic Gender Recognition (AGR) system can be used for improving intelligibility of man-machine interactions, annotating video files or reducing the search space in subject recognition or surveillance systems. In the previous studies, the AGR systems were typically based on only one modality (audio or vision) and their robustness in real-world scenarios was seldom considered. However, in many typical applications, both audio signal and visual signal are available. Ideally, an AGR system should be able to exploit both modalities to improve the overall robustness. In this work, we develop a multi-modal AGR system based on audio and visual cues and present its thorough evaluation in realistic scenarios. First, in the framework of two uni-modal AGR systems, we analyze robustness of different audio features (pitch frequency, formant and cepstral representations) and visual features (eigenfaces, fisherfaces) under varying conditions. Then, we build an integrated audio-visual system by fusing information from each modality at the classifier level. Additionally, we evaluate performance of the system with respect to quality of data used for training the system. We conducted the AGR studies on the BANCA database. In the framework of the uni-modal AGR systems, we show that: (a) the audio-based system is more robust than the vision-based system and its resilience to noisy conditions is increased by modeling only voiced speech frames; (b) in case of audio, the cepstral features are superior to the pitch frequency and formant features, and in case of vision, the fisherfaces outperforms the eigenfaces; (c) for the cepstral features, modeling of higher spectral details and the use of both static and delta coefficients makes the system robust towards noisy conditions. The integration of audio and visual cues yields a robust system that preserves the performance of the best modality in clean conditions and helps in improving performance in noisy conditions. Finally, the multi-conditional training (clean+noisy data) helps in improving performance of the visual features and, consequently, the recognition rate of the audio-visual AGR system.
Technical Reports
Abstract
In this paper, we analyze applicability of F0 and cepstral features, namely LPCCs, MFCCs, PLPs for robust Automatic Gender Recognition (AGR). Through gender recognition studies on BANCA corpus comprising datasets of varying complexity, we show that use of voiced speech frames and modeling of higher spectral detail (i.e. using higher order cepstral coefficients) along with the use of dynamic features improve the robustness of the system towards mismatched training and test conditions. Moreover, our study shows that for matched clean training and test conditions and for multi-condition training, the AGR system is less sensitive to the order of cepstral coefficients and the use of dynamic features gives little-to-no gain. F0 and cepstral features perform equally well under clean conditions, however under noisy conditions cepstral features yield robust system compared to F0-based system.
Abstract
We propose a multi-modal Automatic Gender Recognition (AGR) system based on audio-visual cues and present its thorough evaluation in realistic scenarios. First, we analyze robustness of different audio and visual features under varying conditions and create two uni-modal AGR systems. Then, we build an integrated audio-visual system by fusing information from each modality at the classifier level. Our extensive studies on the BANCA corpus comprising datasets of varying complexity show that: (a) the audio-based system is more robust than the vision-based system; (b) integration of audio-visual cues yields a resilient system and improves performance in noisy conditions.
Research and Projects
My PhD research spans the areas of robotics, computer vision and machine learning. I am interested in developing a representation of household objects that serves a wide range of robotics applications, such as object recognition, inferring object affordances, object grasping and manipulation. I focus on representing visual and depth data as well as tactile information obtained during object grasping. During my master's studies I worked on image and sound processing projects.




Task-based Grasp Adaptation
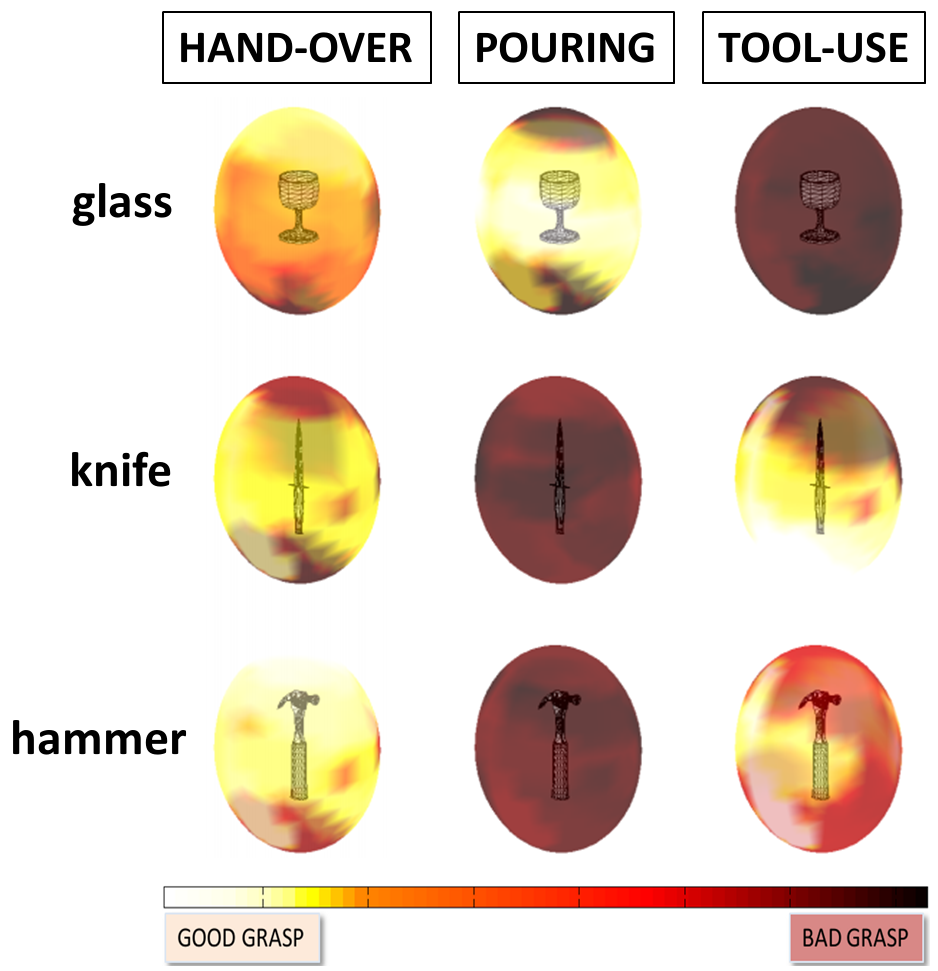
We propose a new approach to grasping objects depending on a performed task. For example, when executing the command "Robot, bring me something to drink from", not every grasp can be applied on an object. The robot should grasp the object that affords drinking (cup, bottle) so that the fingers do not occlude the object opening. Similarly, given the instruction "Robot, drive a screw", the robot should place its hand around the handle of a screwdriver, rather than in its middle, to be able to turn the screw.
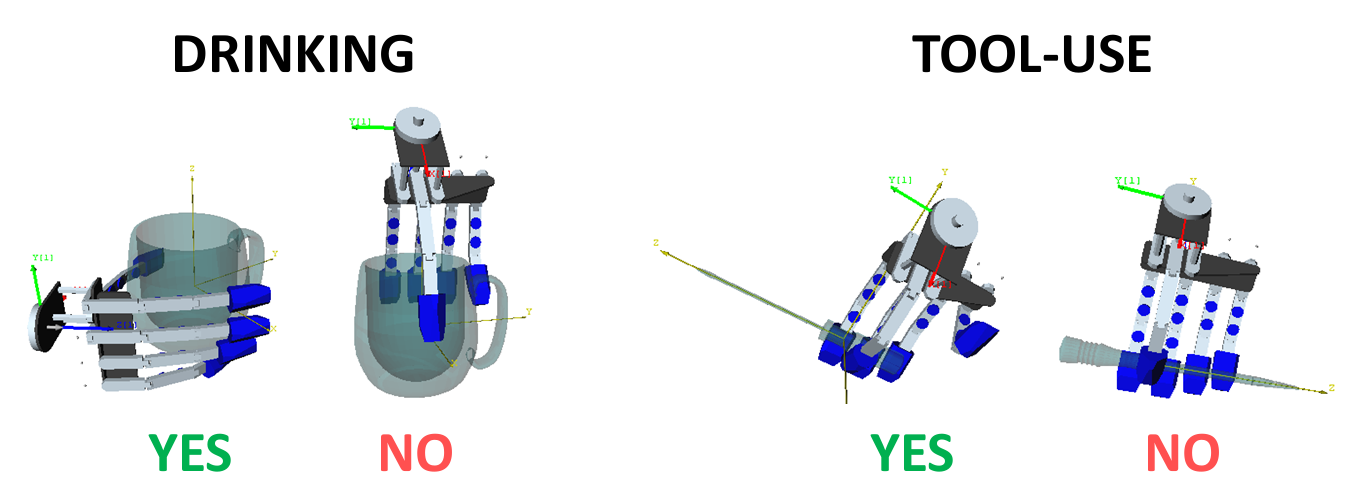
To solve this problem, we exploit the idea of learning grasps using synthetic object models and transferring those grasps to real novel objects depending on their visual properties. Individual object hypotheses are first detected, categorized and then used as an input to the grasp reasoning system that encodes the task information. Our approach not only allows us to find objects in a real-world scene that afford the desired task, but also to generate and successfully transfer task-based grasps within and across object categories.
Our system was implemented on the humanoid ARMAR-IIIa robot. It consists of three components:
(1) active scene segmentation module generating object hypotheses and segmenting them from the background in real time,
(2) object categorization system using integrated 2D and 3D cues, and
(3) probabilistic grasp reasoning system which finds a grasp that satisfies the constraints imposed by the task.
Deep Learning for Tactile Data
In this work, we proposed a new descriptor named the Spatio-Temporal Hierarchical Matching Pursuit (ST-HMP) that captures properties of a time series of tactile sensor measurements. It is based on the concept of deep unsupervised feature learning realized using sparse coding.
The ST-HMP extracts rich spatio-temporal structures from raw tactile data without the need to pre-define discriminative data characteristics. To demonstrate its universal properties, we applied it to two different applications:
(a) object instance recognition, and
(b) grasp stability assessment.
An extensive evaluation on several synthetic and real datasets collected using the Schunk Dexterous, Schunk Parallel and iCub hands shows that our approach achieves state-of-the-art results outperforming previously published methods by a large margin.

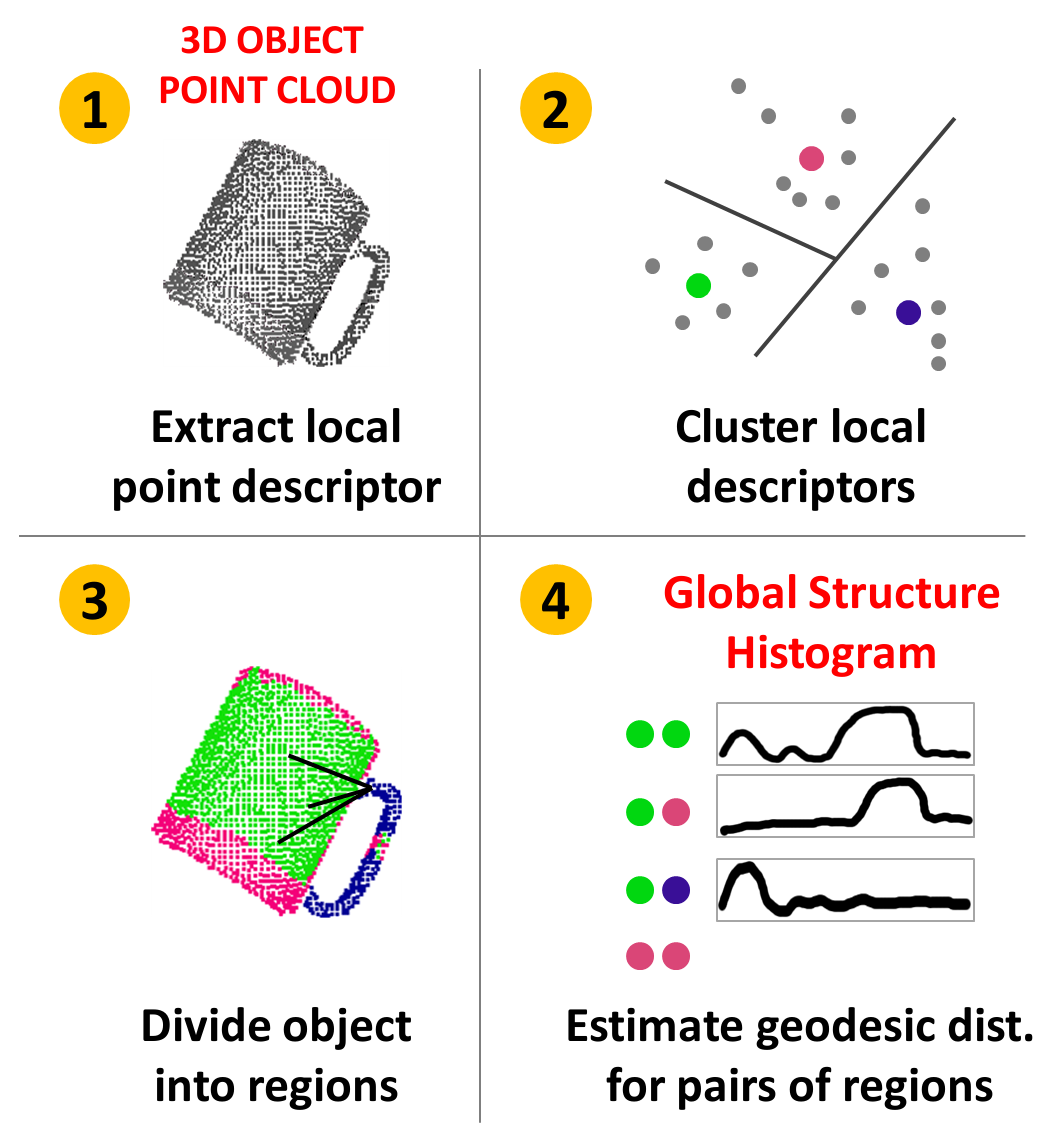
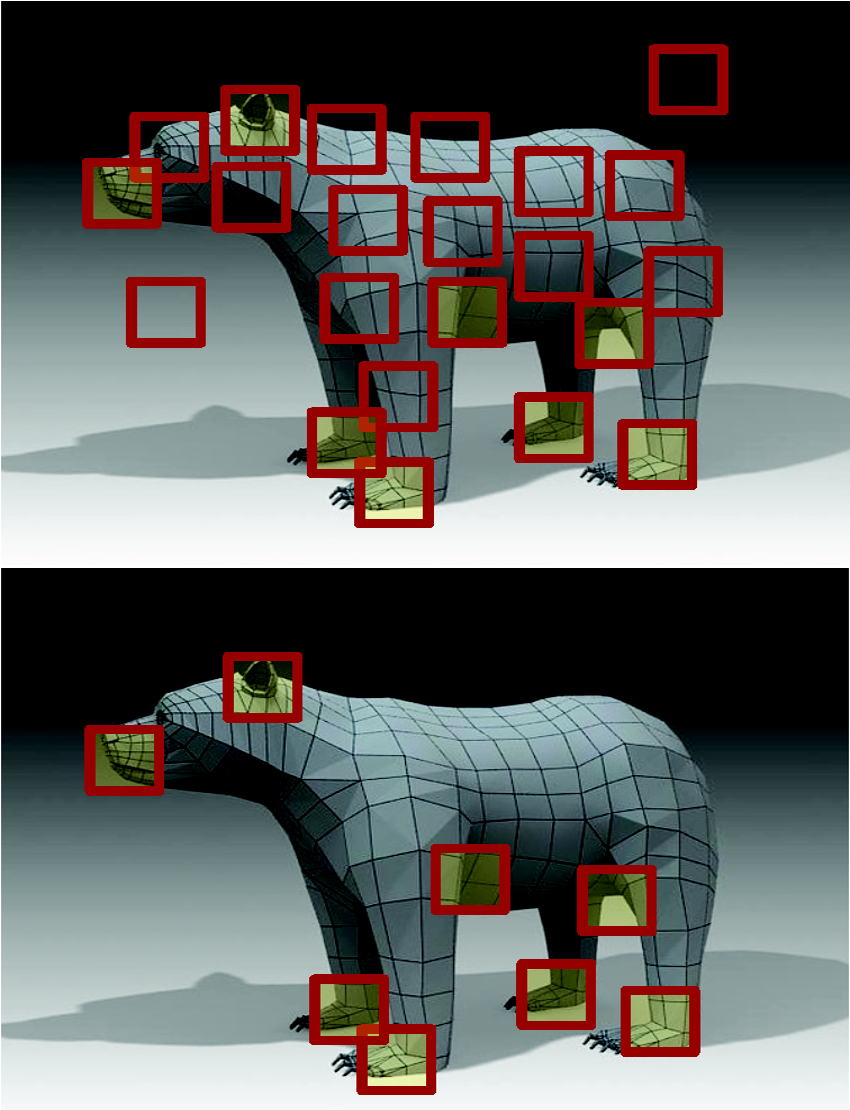
Global Structure Histograms
for 3D Object Categorization
We proposed a new descriptor for 3D point clouds of objects named the Global Structure Histogram (GSH) that encodes the structure of a local feature response on a coarse global scale, providing a beneficial trade-off between generalization and discrimination. Encoding the structural characteristics of an object allowed us to retain low local variations while keeping the benefits of global representativeness. Our object representation is less sensitive to differences in the local object appearance and changes in a camera viewpoint.
We applied the framework to an object category recognition task. In an extensive experimental evaluation in real-world scenarios, we showed benefits of adding the GSH to the local shape descriptors, such as the popular Fast Point Feature Histograms (FPFH) and Radius-based Surface Descriptor (RSD). Moreover, our descriptor demonstrated high robustness to occlusions and camera viewpoint changes significantly outperforming other state-of-the-art global descriptors, such as the Global Fast Point Feature Histogram (GFPFH), Viewpoint Feature Histogram (VFH) and Clustered Viewpoint Feature Histogram (CVFH).
Our work has been a finalist for the CoTeSys Cognitive Robotics Best Paper Award in the IEEE International Conference on Intelligent Robots and Systems (IROS), 2012.
Feature Selection for 3D Object Recognition
Most object classes share a considerable amount of local appearance and often only a small number of features are discriminative. The traditional approach to represent an object is based on a summarization of the local characteristics by counting the number of feature occurrences. In this paper we propose the use of a recently developed technique for summarizations that, rather than looking into the quantity of features, encodes feature quality to learn a description of an object.
Our approach is based on extracting and aggregating only the essential characteristics of an object class for a task. We show how the proposed method significantly improves on previous work in 3D object categorization. We discuss the benefits of the method in other scenarios such as robot grasping. We provide extensive quantitative and qualitative experiments comparing our approach to the state of the art to justify the described approach.

Audio-Visual Gender Recognition
The ability to perform automatic recognition of human gender is crucial for a number of systems that require information about a person. The outcome of an Automatic Gender Recognition (AGR) system can be used for improving intelligibility of human-robot interactions, annotating video files or reducing the search space in subject recognition or surveillance systems.
In this work, we develop a multi-modal AGR system based on audio and visual cues and present its thorough evaluation in realistic scenarios. First, in the framework of uni-modal AGR systems, we separately analyze robustness of different audio and visual features under varying conditions. Then, we build an integrated audio-visual system by fusing information from each modality at the classifier level. We conducted the AGR studies on the BANCA database. We showed that integration of audio and visual cues significantly helps in improving performance in real conditions.
Software
Here you can download open-source software that I have developed under the BSD license. Most of the packages can be also shared or download from my GitHub account: mmadry.
ST-HMP: Spatio-Temporal Hierarchical Matching Pursuit
This package contains implementation of both the Spatio-Temporal Hierarchical Matching Pursuit (ST-HMP) and the Hierarchical Matching Pursuit (HMP) descriptor. Additionally, we provide implementation of a complete classification system in which 3D data matrices (spatio-temporal sequences) are represented using the ST-HMP descriptor. The code can be also used for 2D data matrices (such as images) to directly represent them using the HMP descriptor.
Download the code directly ZIP [12.6MB] or share it on GitHub. Details on how to run the code can be found in the README.md file.
The demo shows how to use the ST-HMP for an object classification task using sequences of real tactile data. It consists of two blocks for:
(1) learning and extracting descriptors:
- the Hierarchical Matching Pursuit (HMP), and
- the Spatio-Temporal Hierarchical Matching Pursuit (ST-HMP)
(2) training and testing the SVM classifiers.
Processing the RGB-D SOC Database
Here is a package that contains tools to process and load the RGB-D Stereo Object Category (SOC) database to the PCL (C++ code) and Matlab.
Download the code directly ZIP [2.6MB] or share it on GitHub. Details on how to run the code can be found in the README files in each directory.
String Kernels
This package contains C++ implementation of a string kernel that allows to compare discrete data sequences of a different length. Additionally, a demo of how to use the kernel for real sentences is provided. For convenience, a computed kernel is saved in the LibSVM kernel format. The string kernel was developed by Craig Saunders.
Download the code directly ZIP [8.2KB] or share it on GitHub.
Databases
RGBD Stereo Object Category (SOC) Database



RGB-D Stereo Object Category (SOC) Database is a collection of RGB images and 3D point cloud data for 140 household objects organized into 14 object categories and 5 task (affordance) classes. The database is designed to be used for Computer Vision and Robotics applications, such as object instance, category and affordance recognition, as well as for grasping and manipulation tasks including transfer of grasp parameter between different objects.
The SOC database consists of two parts: (a) data collected for single objects from various viewpoints, and (b) several natural scenes with multiple and randomly placed objects. It was collected using a humanoid robot Armar III with an online-working segmentation system and we purposely avoided manual object segmentation in order to provide realistic recordings in which both data incompleteness due to occlusions or oversegmentation occur (~15% of data). Moreover, what makes database challenging, objects have highly diverse physical properties (texture, color and shape) and often instances that are visually similar afford different tasks.
- Download
- Individual Objects (5.2GB) and the description of the database structure PDF
- Multiple Object Scenes (0.5GB)
- For convenience, we provide tools to process data in the PCL and Matlab. Software on GitHub or download directly.
- Publications
- M. Madry, D. Song and D. Kragic, "From object categories to grasp transfer using probabilistic reasoning". In IEEE International Conference on Robotics and Automation (ICRA), 2012.
PDF Bibtex Video
If you use the SOC database please cite the following paper:
- The database have been also used in the following publications:
- M.Madry, D. Song, C. H. Ek, D. Kragic."Robot, bring me something to drink from": object representation for transferring task specific grasps". In IEEE ICRA-2012, Workshop on Semantic Perception, Mapping and Exploration (SPME), 2012.
PDF Bibtex - M. Madry, C. H. Ek, R. Detry, Kaiyu Hang, D. Kragic, "Improving generalization for 3D object categorization with Global Structure Histograms". In IEEE International Conference on Intelligent Robots and Systems (IROS), 2012.
PDF Bibtex - M. Madry, H. Maboudi Afkham, C. H. Ek, S. Carlsson, D. Kragic, "Extracting essential local object characteristics for 3D object categorization", In IEEE International Conference on Intelligent Robots and Systems (IROS), 2013.
PDF Bibtex
More Details
Database contains 14 object categories: ball, bottle, box, can, toy-car, citrus, mug, toy 4-legged animal, mobile, screwdriver, tissue, toilet-paper, tube and root-vegetable, each with 10 different object instances per category. In total, we collected data for 140 objects. For each object, there are RGB images and 3D point clouds in 16 different views around an object (separated by 22.5°) recorded using the 7-joint Armar III robotic head with foveal and peripheral stereo cameras. To differentiate an object and background, we used the active segmentation method by Bjorkman et al.

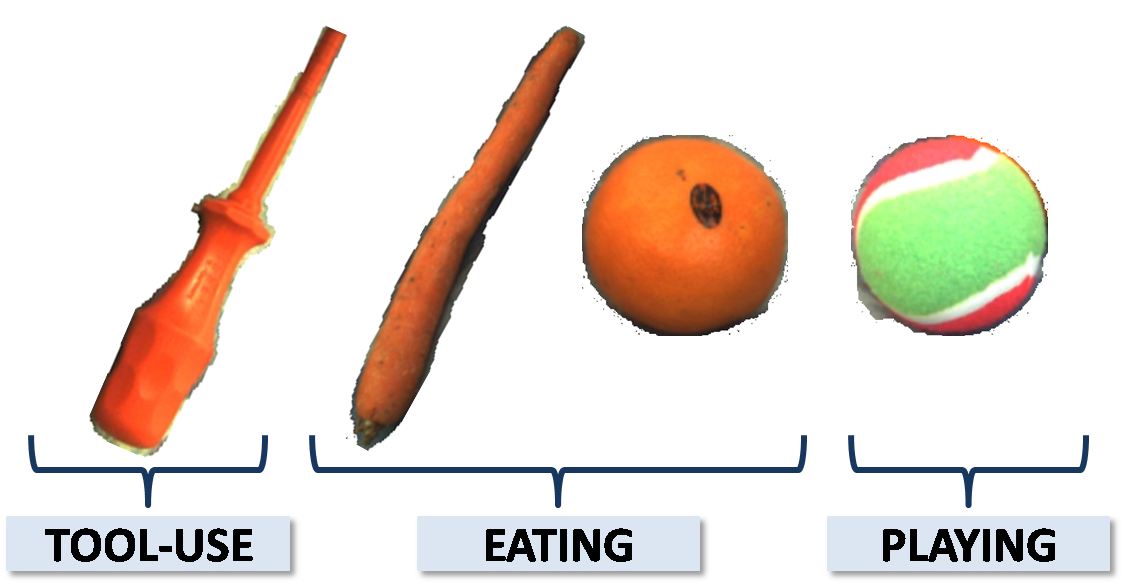
We suggest to divide objects into 6 affordance classes according to the tasks:
(1) pouring: bottle, mug
(2) playing: ball, toy-car, toy-animal
(3) tool-use: screwdriver
(4) dishwashing: mug
(5) eating: citrus, root-vegetable
(6) hand-over: all object categories.
Please note that objects that are visually alike may have different functionality. An example can be a screwdriver and a carrot that have a similar shape, but only the former can be used as a tool; or a ball and an orange where only the former affords playing. Moreover, objects that have different shapes can afford the same task such as eating in case of a carrot and an orange.

In order to evaluate performance in the real environment, we collected data for several natural scenes that include data for 245 objects recorded from random viewpoints and scales. Five subjects were asked to randomly place between 10 to 15 objects from 14 different categories on a table. In the scenes, different lightning condition and occlusions of objects are present. Examples of the scenes in peripheral and foveal views, and segmentation, depth and left-right stereo images are presented below.






Teaching
Courses
- I have designed and taught the PhD-level course during my PhD at the Royal Institute of Technology (KTH):
- DD3315 Multiple View Geometry in Computer Vision.
- I have been also a teaching assistant for the undergraduate course for a few years:
- DD2423 Image Processing and Computer Vision.
Student Supervision
- There have been a number of excellent undergraduate students that I got the chance to supervised or co-supervised:
- Golnaz Nozari, "Category-based object pose estimation", Master's thesis in 2012. Golnaz is currently a software developer at Nexus Technology.
- Kaiyu Hang, "Combining Global Structure Histograms with the Radius-based Surface Descriptor for 3D object categorization", summer project in 2011; co-supervised with Carl Henrik Ek. Hang is currently a PhD student at CVAP.
- Cheng Zhang, "Object categorization for action recognition", summer project in 2010; co-supervised with Hedvig Kjellstrom. Cheng is currently a PhD student at CVAP.
Contact
How to reach me?
[email protected]
m_madry
KTH Address
Teknikringen 14, CVAP-Lab: 715, Stockholm, Sweden
CVAP / CSC / KTH, SE-100 44 Stockholm, Sweden
Currently, I'm at the University of Washington, USA
Paul Allen Building, RSE-Lab: 491
185 Stevens Way, Seattle, USA